



Tales from the jar side: Claude Code, DeepSeek Fill-in-the-Middle API, New video, Open book and AI exams, and the usual silly toots and skeets
I was once arrested for stealing a kitchen implement, but it was a whisk I had to take (rimshot)

Welcome, fellow jarheads, to Tales from the jar side, the Kousen IT newsletter, for the week of February 23 - March 2, 2025. This week I taught my regular courses at Trinity College (Hartford).
Claude Code
I use two different AI tools integrated into my development environment. The tools are GitHub Copilot and the JetBrains AI Assistant. Each has its own roles. I use Copilot mostly for code assist — whenever I pause, it suggests continuations in italics, which I either accept by hitting TAB or reject using ESC. I mostly use AI Assistant for it’s excellent ability to generate git commit messages (the ones from Copilot are much less thorough) and for analyzing errors. Each also provides a chat box, which I can use to ask questions or request specific methods.
What neither tool does is something I’ve wanted for a long time: examine my entire project. Both tools are restricted to a single file, or even a portion of a file, unless I copy tons of code and paste it into the chat box.
I was therefore surprised to discover that Anthropic, the AI company behind the Claude tool, released something called Claude Code. Claude Code was apparently released on Feb 24, about the same time they announced Claude 3.7 Sonnet, which made a huge impact on the AI world. I only heard about it yesterday, and decided to try it out.
Claude Code is an example of an AI agent, which is a program that takes actions on your behalf. Claude Code adds AI integrations to the command line. Once you’ve installed Claude Code, you change directory to the root of your project, start up the tool with the claude command, and start asking question. You can generate implementations, run tests, and even commit the results to a git repository. Claude carries out all the actions based on your permissions, which you give it when you first authenticate.
You install the tool very simply:
$ npm install -g @anthropic-ai/claude-codeThat means it’s a node application, implemented in JavaScript. The tool warns you that it’s only in beta, requires you to authorize it to work with your code, asks you to choose a font color, and you’re off and running.

The key feature to me is that it has access to the entire project in that directory.
As a trial, I went to one of my projects and did the following:
Asked it to evaluate the code coverage metrics for my tests in the project.
Asked it for suggestions to improve them.
Had it generate a few tests to satisfy the gaps. This didn’t work right away, so it diagnosed the problems, rewrote the code, and fixed the tests. Eventually they all worked correctly.
Committed the changes to my repository and pushed them to GitHub.
That all took about 12 minutes of real time, and about 4 minutes of API time. The charges are done through the API. Claude Code uses Claude 3.7 Sonnet, which charges $3 / million input tokens and $15 / million output tokens, which comes down to fractions of a cent per request. Still, when you’re working with an entire code base over a period of time, they add up.
That little exercise I ran cost me $1.19. I think I can handle that.
I rarely spend more than a dollar on Claude API access in a month. I think that’s about to change.
I managed to record a video about all of this, but it still needs editing, so it’s not yet released. I’ll include a link in next week’s newsletter.
Claude 3.7 Thinking Model
Speaking of Claude 3.7 Sonnet, I did manage to record a video about it this week:
The video is only a bit about the thinking model. What it’s really about is the issue I discussed here last week, which is that the thinking model in Claude adds JSON properties to both the input requests and the output responses which are not mapped to Java classes by LangChain4j. I demonstrated how to use the Jackson JSON parser directly to access those properties and work with them.
The number of views so far have been … okay. While I used the new “thinking” capability of Claude as a demo, the real topic is all that simple JSON processing in Java needed to access those unmapped properties. I may need to give the video a new title as a result, but I’m not sure yet.
DeepSeek FIM
I mentioned recently that when you examine the API for the DeepSeek models (the basic V3 model and the slick new R1 reasoning model), they reused most of the OpenAI approach. If you are a Python or JavaScript developer, you can use the regular OpenAI library, and just change the base URL, the API key, and the model to DeepSeek values, and you’re ready to go.
There is one capability, however, that DeepSeek provides that none of the other AI models has. It’s called FIM, which stands for Fill-in-the-Middle.

The way to call it, after setting the proper parameters listed above, is to give it a prompt, which is the start condition, and a suffix, which is the end condition, and DeepSeek fills in the middle.
The example they used in their documentation was for the body of a Fibonacci calculator, presumably for use by a code assist tool:
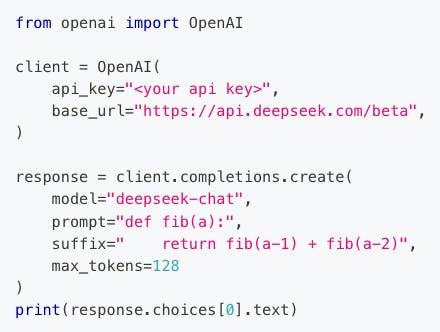
The output of that Python script is:
if a == 1 or a == 2:
return 1Okay, that seems straightforward enough. I mean, I wouldn’t want to use the recursive implementation of Fibonacci for anything but very small numbers because it’s very inefficient, but this works.
I decided to try it on a couple of different options.
Here are the prompts:
prompt = "Once upon a time"suffix = "And they lived happily ever after"
Here’s the result:
Once upon a time
there was a boy and a girl
They fell in love
And they lived happily ever afterI guess that works. The first time I tried it I got a long story about a girl with a magic loom, but I’m glad I don’t need to include that whole thing here.
Of course, I had to try this:
prompt = "Phase 1: Steal underpants"suffix = "Phase 3: Profit"

The result came back almost immediately: “?”
Okay, so apparently it gets South Park references, or at least it got that one.
The question in my mind was, why make a whole API endpoint just to do this? It’s not like it’s difficult to make a prompt on some other tool like, “Complete the text that would connect these two passages: START {prefix} MIDDLE {suffix} END”. Perplexity suggested four possible reasons:
1. Developer convenience: It provides a cleaner interface that explicitly communicates the intended use case
2. Marketing differentiation: Having named capabilities helps position the API in a competitive market
3. Potential minor optimizations: There might be small tweaks to how the model processes these requests, though the benefits are likely marginal
4. Historical precedent: FIM has been a named capability in some research contexts, so maintaining that terminology provides continuity
Yeah, I don’t know. Seems like a lot of extra work for just that, but maybe they have some plan I’m not seeing. The funny part for me is that the rest of the DeepSeek API is based on OpenAI, but this is wholly their own, so they really had to want to do it. I guess I’ll wait and see. In the meantime, this will probably become its own video, too.
Students and Open Book Tests
I decided to give my Artificial Intelligence students at Trinity College a short quiz on the Deep Learning material we covered so far in the course. Of course I used Claude 3.7 Sonnet to generate most of the questions after pasting in the material we covered from our text, Build a Large Language Model From Scratch.
I edited the questions, of course, and it’s a good thing I did. Despite how good the new models are, they still make basic math mistakes. I managed to catch one and update it, which it apologized for, as usual.
I generally make those quizzes open book, open notes, open AI, etc. All that meant I had no idea how long the quiz was going to take. Eventually I settled on 20 questions and gave them 75 minutes (our normal class time) to do it, so that’s 3.75 minutes a question.
As it turned out, everyone finished between minute 20 and minute 40, and all the scores were 18 / 20 or higher. I guess that means today’s students are pretty good at answering open book quizzes, especially if they have an AI at hand to ask, which I assume most of them did.
I suppose I could have tried to avoid giving them access to AI tools, but I consider an important part of their training to be learning how to use those tools productively. As I’ve said before, I believe the way they should market themselves is not as junior developers, but as very young senior developers who manage a staff of AI tools. In today’s market, I think that’s their best option.
I should also mention that on Tuesday, we had a guest lecture by Sebastian Raschka, the author of the book mentioned above. This impressed the students greatly, not necessarily because of the quality of his lecture (which was very good, of course), but because he’s apparently something of a celebrity. If you check out his LinkedIn page, you’ll see:

Yeah, he’s got over 150K followers. That’s a lot, especially for a software developer. My students wondered how I got him to agree to speak. The truth is that I just reached out and asked, and told him I was using his book in my class. If the reflected glory from that makes me go up in my students’ eyes, I can live with that. :)
Toots and Skeets
Clever

As we all know, the jarheads who read this newsletter are by far the most intelligent, sophisticated, and, of course, good looking newsletter readers in the history of the Internet. They’re also far too knowledgeable to fall for such abject pandering.
Put a ring on it
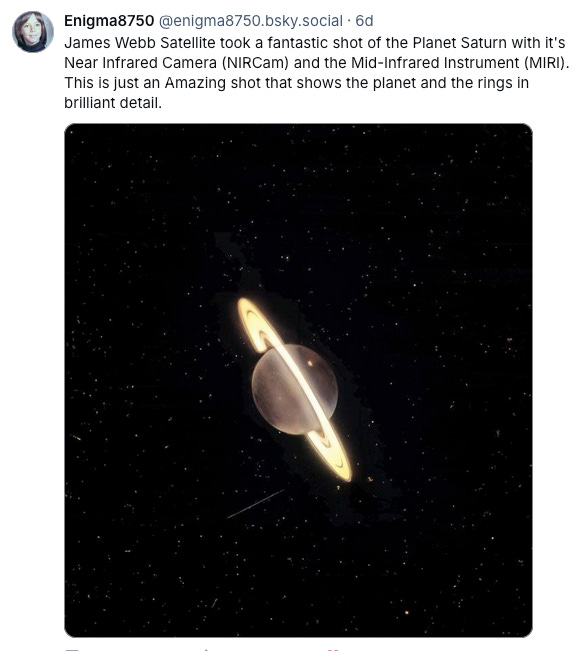
Seriously, I had no idea the JWST was going to take such amazing pictures of planets in our own solar system. Awesome barely covers it.
What I did this week

To think Elon telling every government employee to justify their existence in an email guaranteed to be checked by AI was only the second stupidest or most offensive thing the administration did this week. But I can’t speak rationally yet about their obvious Russian operation to sabotage the incredibly brave leader of a country fighting for its life. I’ll just leave it at this:

Back to the severed floor

Yeah, like so many people, I’m hooked on the Apple TV show Severance. I intended to re-watch the first season over a couple of weeks, but wound up binging it again. This season has been every bit as good, though the latest episode was tough. They have to rescue Gemma somehow.
In the meantime, there’s this:

Yeah, that’s eight hours of Severance-based music. I played the whole thing as background music while working this week.
FYI, Lumon Industries has a LinkedIn page:

They aren’t listing any job openings at present, but I know there’s at least one in Macrodata Refinement and one in Optics and Design.
Old song reference of the week
Rimshot.
Finally, a horrible joke that my wife will definitely laugh at

Sigh. Have a great week everybody.
Last week:
My regular Trinity College schedule
This week:
The Devnexus conference in Atlanta
My regular Trinity College schedule